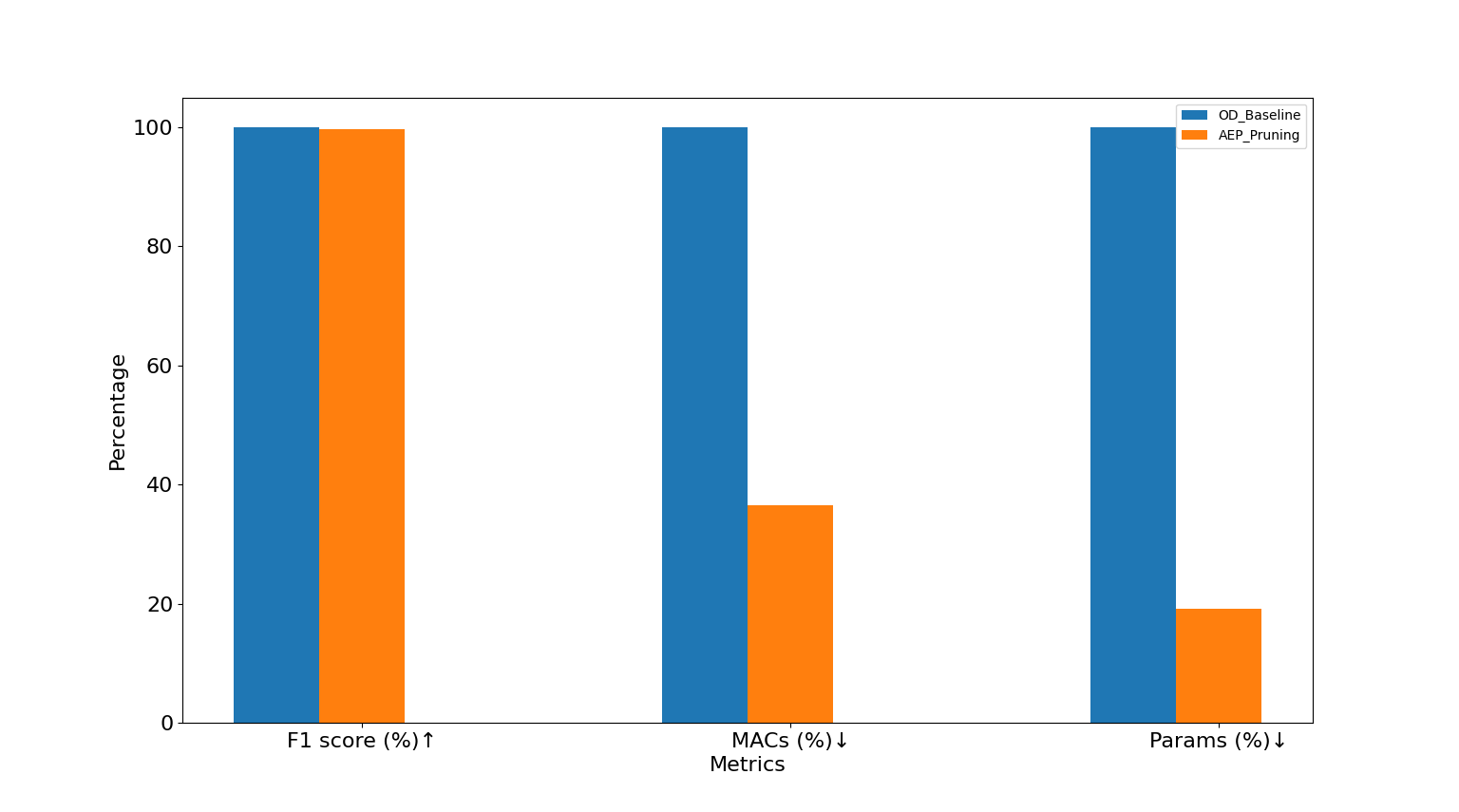
現在の大規模なディープラーニングモデルは、複雑なネットワーク構造によって精度を向上させていますが、実行速度が犠牲になり、パラメータ数も増加しています。この問題に対処するため、ディープラーニングモデルをより軽量かつ効率的にするプルーニング手法を採用しました。
プルーニングは木の剪定のようなもので、モデル内の不要な部分を削除して構造を簡素化し、その結果、推論速度を向上させつつメモリ使用量を削減します。この手法はモデルの効率を高めるだけでなく、リソース消費も抑えるため、計算リソースが限られたハードウェアプラットフォームへのモデル実装に適しています。
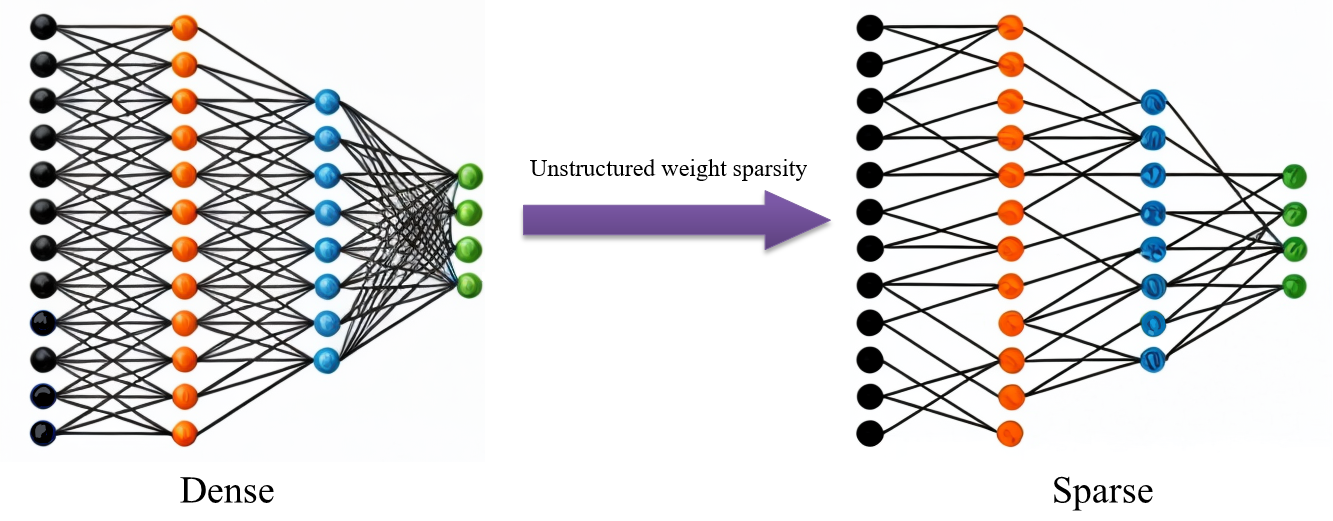
当社の技術要素:
スパース学習:学習過程で不要な重みや接続を段階的にゼロ化(スパース化)することで、より小型で効率的なモデルを実現します。スパース学習は、モデルの性能を維持しながら、計算コストとメモリ使用量を大幅に削減できます。
構造化プルーニング:ニューロンや畳み込みフィルタを構造単位で丸ごと削除して、モデルの複雑さを軽減する手法です。プルーニング後も規則的な構造を維持するため、ハードウェアアクセラレータやディープラーニングフレームワークの最適化に役立ちます。
プルーニング後のファインチューニング: プルーニングによって生じた性能低下を回復させ、モデルの精度と安定性を確保します。

これらの技術を組み合わせることで、モデルのリソース要件を大幅に削減しながら性能を保ち、実運用プラットフォームへのモデル実装に有効なソリューションを提供します。