AIモデルの学習には、十分なデータを収集するために多くの人材が必要です。AIモデルに実環境のシナリオを学習させるには多様なデータセットが求められますが、実際には入手の難しいデータも少なくありません。そこで、これまでは従来の画像拡張技術を用いられることがよくありました。しかし、この手法では多様性の要件を満たすには限界があります。
この問題を解決するため、従来の画像拡張技術に代わる生成AIを開発しました。生成AIはより多様でリアルな画像を作成でき、データセットの品質を高めるとともに、AIモデルに現実世界のさまざまなシナリオを学習させます。生成AIの活用により、必要なデータをより効率的に取得でき、要していた人手を削減することが可能になります。
方法
最新の生成 AI には、オートエンコーダー (AE)、変分オートエンコーダー (VAE)、敵対的生成ネットワーク (GAN)、正規化フロー、拡散モデルなど、さまざまなタイプがあります。
これらのモデルは、製品のニーズと利用可能なリソースに応じて、noise-to-image、text-to-image、image-to-image などのタスクで学習させることができます。
当社の製品では、image-to-image 学習手法を採用しています。ペアデータセットを用いてモデルを学習させることで、入力側で生成画像の輪郭(アウトライン)を正確に制御し、天候やシーンの変更といったスタイル変換にモデルを活用します。この方法は生成画像の品質を高めるだけでなく、モデルの柔軟性と適用範囲を広げ、多様な製品要件に対応します。
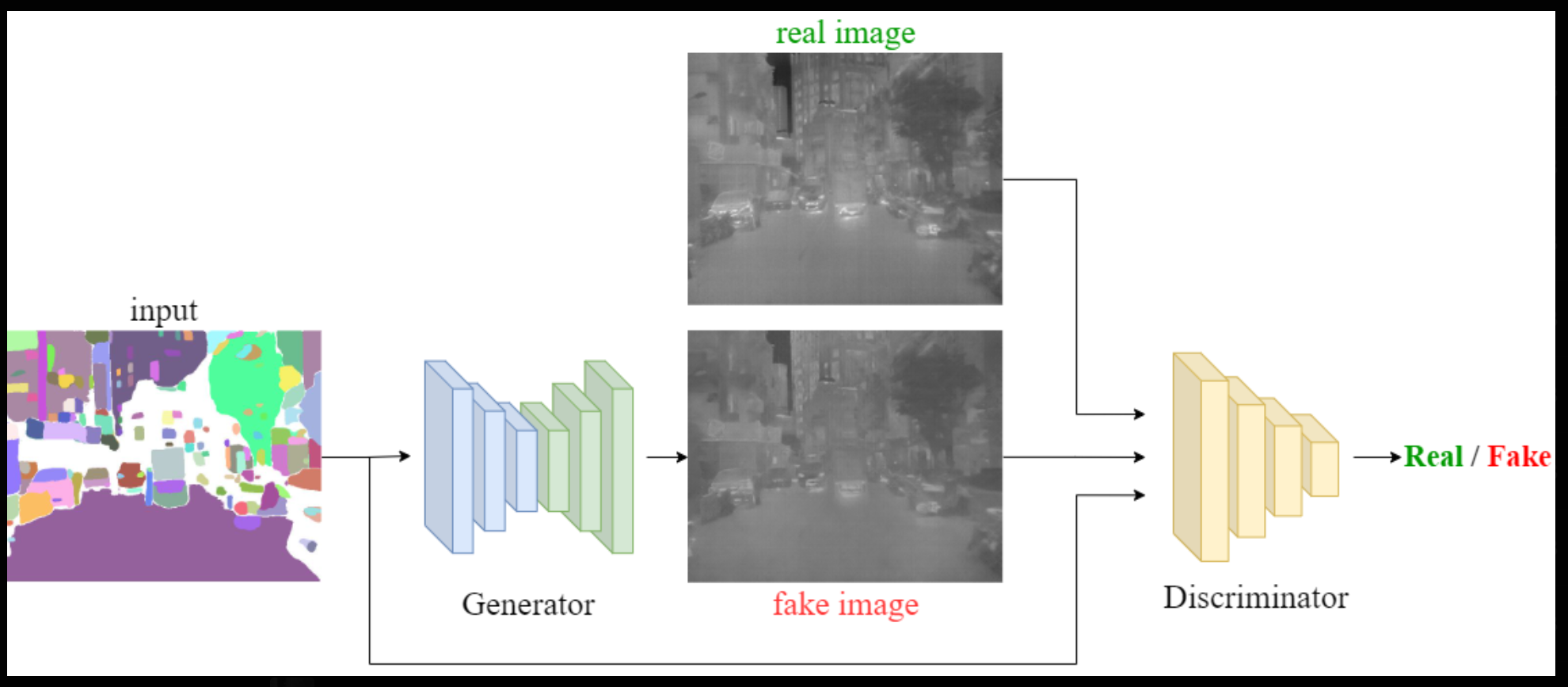
成果
