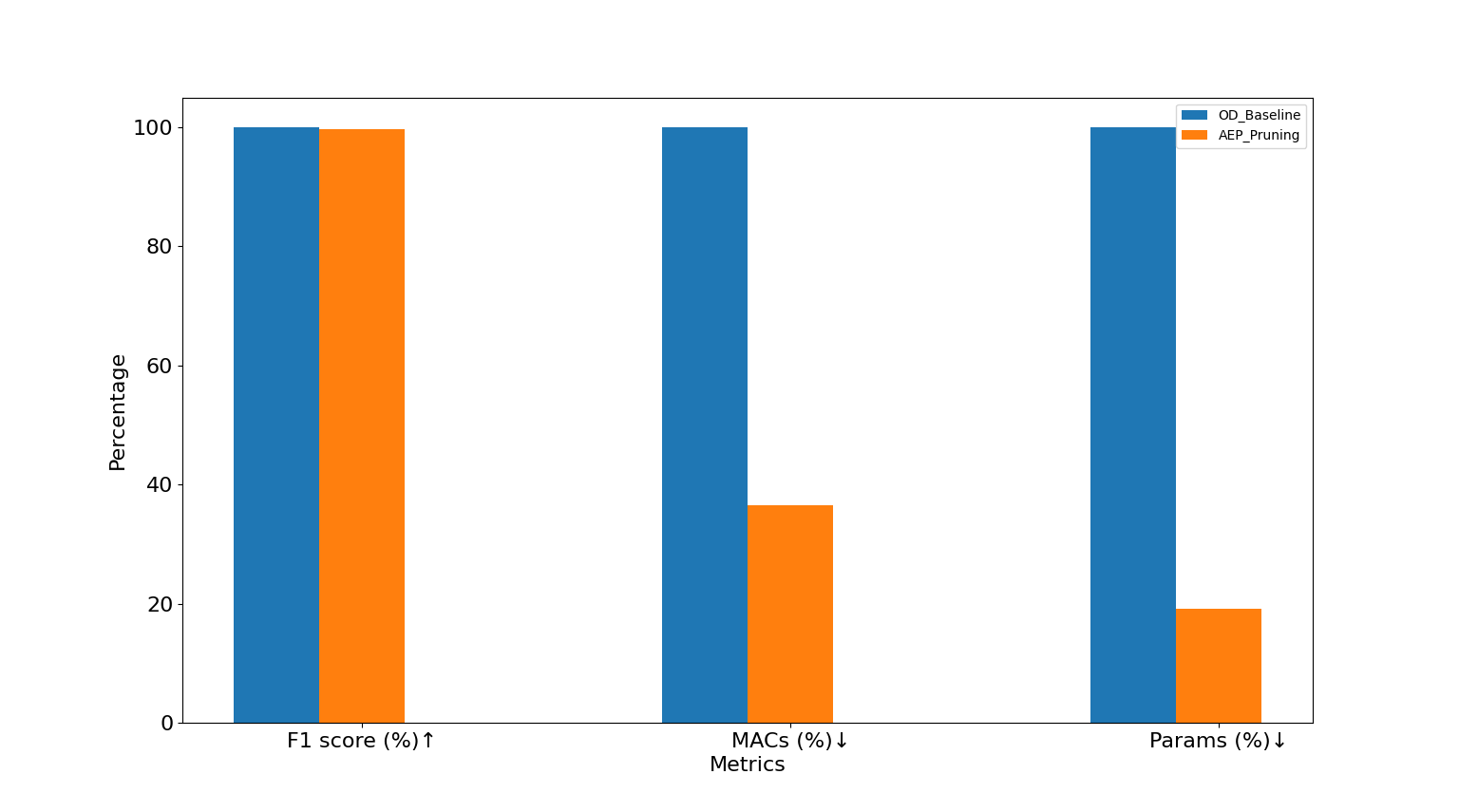
當前的大型深度學習模型通過複雜的網絡結構提升準確度,但也因此犧牲了運行速度並增加了過多的參數量。為了解決這一問題,我們採用了「剪枝」(Pruning)技術,使深度學習模型變得更加輕便且高效。
剪枝技術就像修剪樹木,移除不必要的部分,使模型結構簡化,從而提升運行速度並減少記憶體佔用。這項技術不僅提高了模型的運行效率,還減少了資源消耗,特別適合部署在資源有限的硬體平台上。
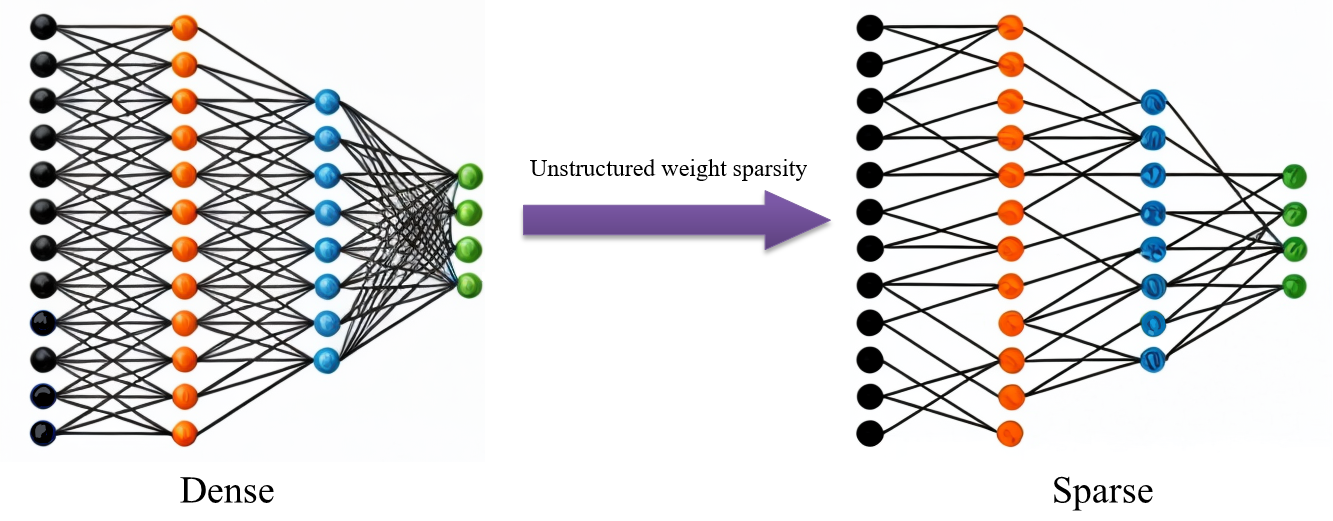
我們的技術包含了:
稀疏化訓練(Sparse Training):通過在訓練過程中強制模型保持稀疏性來逐步減少不必要的權重,從而自然地形成一個更小且更高效的模型。稀疏化訓練能顯著降低計算成本和內存佔用,同時保持模型性能。
結構化剪枝(Structured Pruning):根據模型結構移除整個神經元或卷積核,以減少模型的複雜度。結構化剪枝的特點在於剪枝後的模型仍然具有規則的結構,有助於硬體加速器和深度學習框架的優化。
剪枝後微調(Fine-Tuning):在剪枝後對模型進行微調,以恢復因剪枝而略有下降的性能,確保模型的精度和穩定性。

通過這些技術的結合應用,我們能夠在保持模型性能的同時,大幅度降低其資源需求,為實際應用中的模型部署提供了有效解決方案。這些方法使我們能夠在各種資源受限的環境中部署高效的深度學習模型,滿足現代應用的需求。