訓練 AI 模型需要大量的人力資源來獲取足夠的資料量,為了讓 AI 模型能夠更好地學習真實世界的狀況,我們需要擁有多樣性的資料集。然而,現實中許多類型的資料並不容易獲取,因此傳統影像擴增技術經常被用來增加資料量,但這些技術在多樣性要求方面存在局限性。
為了解決這一問題,我們使用生成式 AI 來取代傳統的影像擴增技術。生成式 AI 能夠創建出更加多樣化且具有真實感的影像,不僅提高了數據集的品質,還使得 AI 模型在學習時能夠更好地應對各種真實世界的情況。通過這種方式,我們能夠更高效地獲取所需的數據,同時減少人力資源的消耗。
方法
現今的生成式 AI 包括多種不同類型,常見的有自動編碼器(Autoencoder, AE)、變分自動編碼器(Variational Autoencoder, VAE)、生成對抗網絡(Generative Adversarial Networks, GAN)、正規化流(Normalizing Flow)和擴散模型(Diffusion Models)。
這些模型的訓練方式可以分為雜訊到影像(noise-to-image)、文本到影像(text-to-image)和影像到影像(image-to-image)等不同的任務。
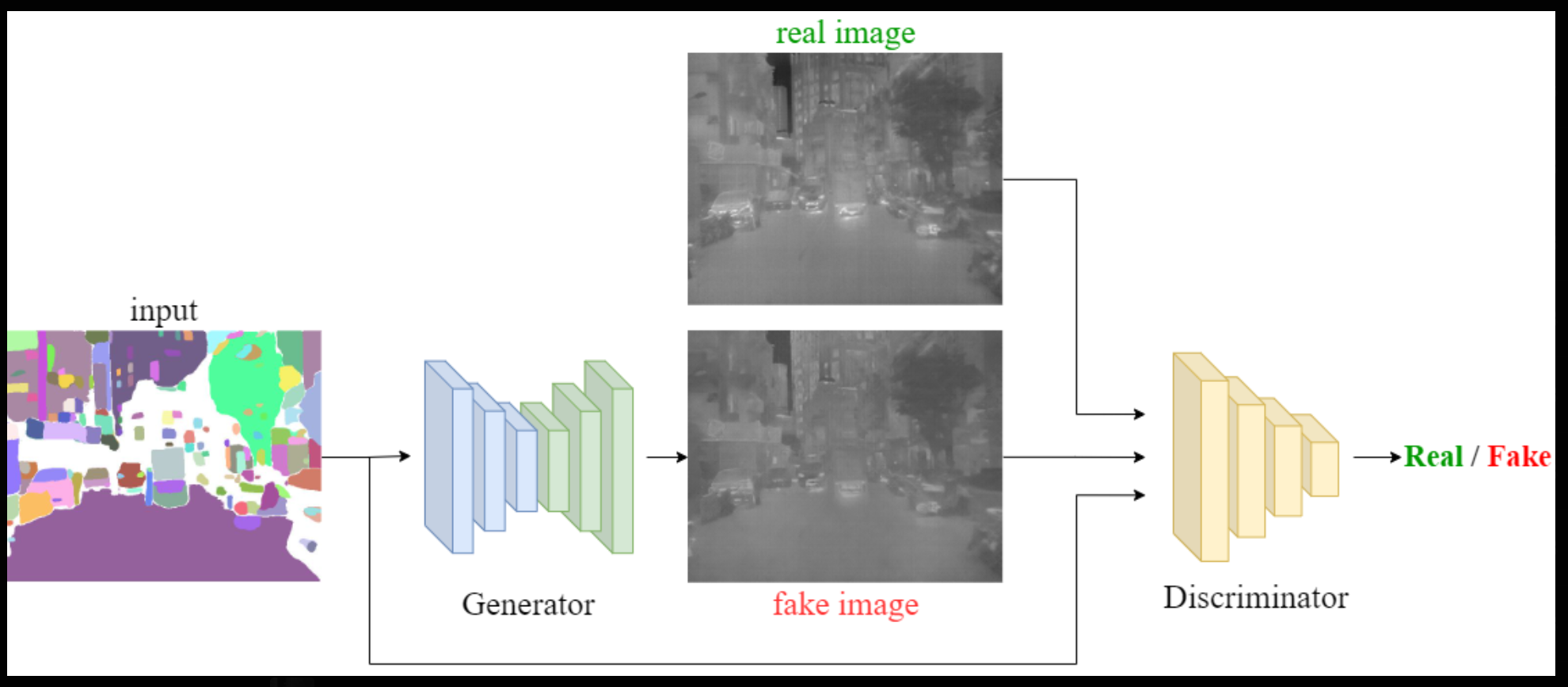
在開發過程中,我們選擇了影像到影像(image-to-image)的訓練方式。通過使用成對的資料集訓練模型,我們能夠在輸入端精確控制生成影像的輪廓,並利用模型進行風格轉換,如天氣和場景的變換。這種方法不僅提升了生成影像的品質,還增強模型的靈活性和應用範圍,滿足了多樣化的產品需求。
結果
